Hermes - Rich Web
Usually, easy reachable articles and videos, related to various topics, are not meaningful in respect to the time needed to consume them. Bubbling. Many are similar in a way that is not important which one you choose, similar ideas, nearly identical story flow. Shortly after consumption, I forget that I ever reached that material — no thought-provoking ideas.
Like George Hotz said in one of his live sessions, I also like text-rich web pages with minimal web components — how old web looks like. The author of a blog post or essay should focus on paragraphs with few graphics and not worrying too much about style or trying to sell something at the end. I would like to find a systematic way to reach that golden nectar.
To get golden nectar, we need to create a clear objective. For now, I will only focus on page structure. My analysis is staring with my favorite websites that you can find in the configuration file.
Methodology
To reach our goal, we should define “good page” mathematically. We will score the page and if that score is lower than given thrash hold, which we determined empirically, we will keep that page in our record. The proposed formula is bellow, each variable represents the number of specific entities.
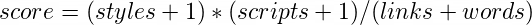
We can not reach all pages1, so instead of extracting links from each visited page, I use probability condition to check is page suitable for further exploration
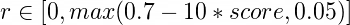
where r represents random number from uniform distribution. If above condition is satisfied, page is suitable.
Implementation
Complete solution is implemented in one Python script, which you can find on the link. Implementation is pretty straightforward. The solution is logically divided into two segments: collector and page workers. Collector workers fetch web pages and pass them to page workers, which analyze page’s content and extract hyperlinks.
The proposed solution is supplemented with an additional script, that generates a page with a representation of the final result.
Results and discussion
After a few runs, I have analyzed fetched websites and got some impressive results. Below, you can see some interesting websites. For example, one that is talking about website obesity is a website that is covering ideal that I’m striving for in this article!
- https://idlewords.com/talks/website_obesity.htm
- http://www-pw.physics.uiowa.edu/space-audio/sounds/
- https://nssdc.gsfc.nasa.gov/planetary/lunar/apollo8info.html
- https://www.defectiveyeti.com/archives/cat_favorite_posts.html
Because the proposed model prefers long articles, I get also some user manuals and using policies — which are not that useful. That could be avoided by semantic analysis, but that will also make the proposed model much more complex.
In this attend, I focused on website structure as a measure of suitability, words and sentences are to a great degree out of consideration. Elegant approach, that should improve results, is using deep neural networks — but for that I need to create annotated dataset, which consumes a lot of time. That could be a topic in some of following articles.
Full implementation available at following link. Till the next time, cheers!

hardware limitations ↩︎